产品发布 · 小互解读
Claude 4 发布:双模型主攻编程与 Agent
Opus 4、Sonnet 4 在 SWE-bench 分别拿 72.5% 和 72.7%;定价沿用上代,Sonnet 4 免费用户也能用。
速览
- Anthropic 发布 Claude Opus 4 和 Claude Sonnet 4 两款模型,主打编程、推理和 AI Agent。
- Opus 4 在 SWE-bench 拿 72.5%、Terminal-bench 43.2%,官方称是「全球最强编程模型」;Sonnet 4 在 SWE-bench 拿 72.7%。
- 两款都是混合模型,支持「即时回答」和「扩展思考」两种模式,扩展思考期间还能调用工具(如网页搜索)。
- 定价沿用上代:Opus 4 每百万 token 输入/输出 $15/$75,Sonnet 4 为 $3/$15;上 API、Bedrock、Vertex AI,Sonnet 4 对免费用户开放。
- Claude Code 正式版上线,支持 VS Code/JetBrains 插件、GitHub 后台任务,并开放 SDK。
⚑
这是 Anthropic 官方发布通稿。模型能力、benchmark 得分、「全球最强编程模型」等表述均出自厂商,benchmark 为官方自测,合作方评价多为单方说法。下文已把官方确认与外界推测分栏对照。
长任务进度轴:Opus 4 能在上千步、连续数小时的任务上推进,途中把关键信息写成「记忆便签」存下来,回头再翻,保持前后连贯。
这次 Anthropic 一口气发了两款模型。Opus 4 定位最强编程,能在需要上千步、连续干几个小时的长任务上保持状态;Sonnet 4 是 Sonnet 3.7 的升级款,编程和推理更强、更听指令,主打性价比和日常使用。两款都是「混合模型」:同一个模型既能秒回(即时回答),也能切到「扩展思考」模式做更慢、更深的推理。
一个模型,两种模式
即时回答
直接给答案,快,适合日常问答和简单任务。
扩展思考
先在内部推理一段再作答,处理更难的问题。
这一代的新东西是,扩展思考时模型能边想边用工具。以前要么先想完再答,要么单独调个工具拿结果;现在它可以在思考过程里穿插调用网页搜索等工具:想一段,去查点资料,拿回结果接着想,直到给出答案。下面是这个交替过程:
推理THINK
→
调用工具网页搜索等
→
拿到结果RESULT
→
继续推理THINK
→
给出答案ANSWER
↺ 推理与工具调用交替进行,直到答案成形
记忆文件
另一项升级是记忆。当开发者给模型本地文件的读写权限后,它会把关键信息写进「记忆文件」存着,跨长任务保持连贯,把零散经验慢慢攒成默会知识。官方还称两款模型在容易钻空子的 Agent 任务上,走捷径、钻漏洞的概率比 Sonnet 3.7 低 65%。
打个比方
模型的「记忆文件」就像做长期项目时随手记的工作笔记本,把关键信息写下来存着,过一阵回来翻一翻,不至于把前面做的事忘光。
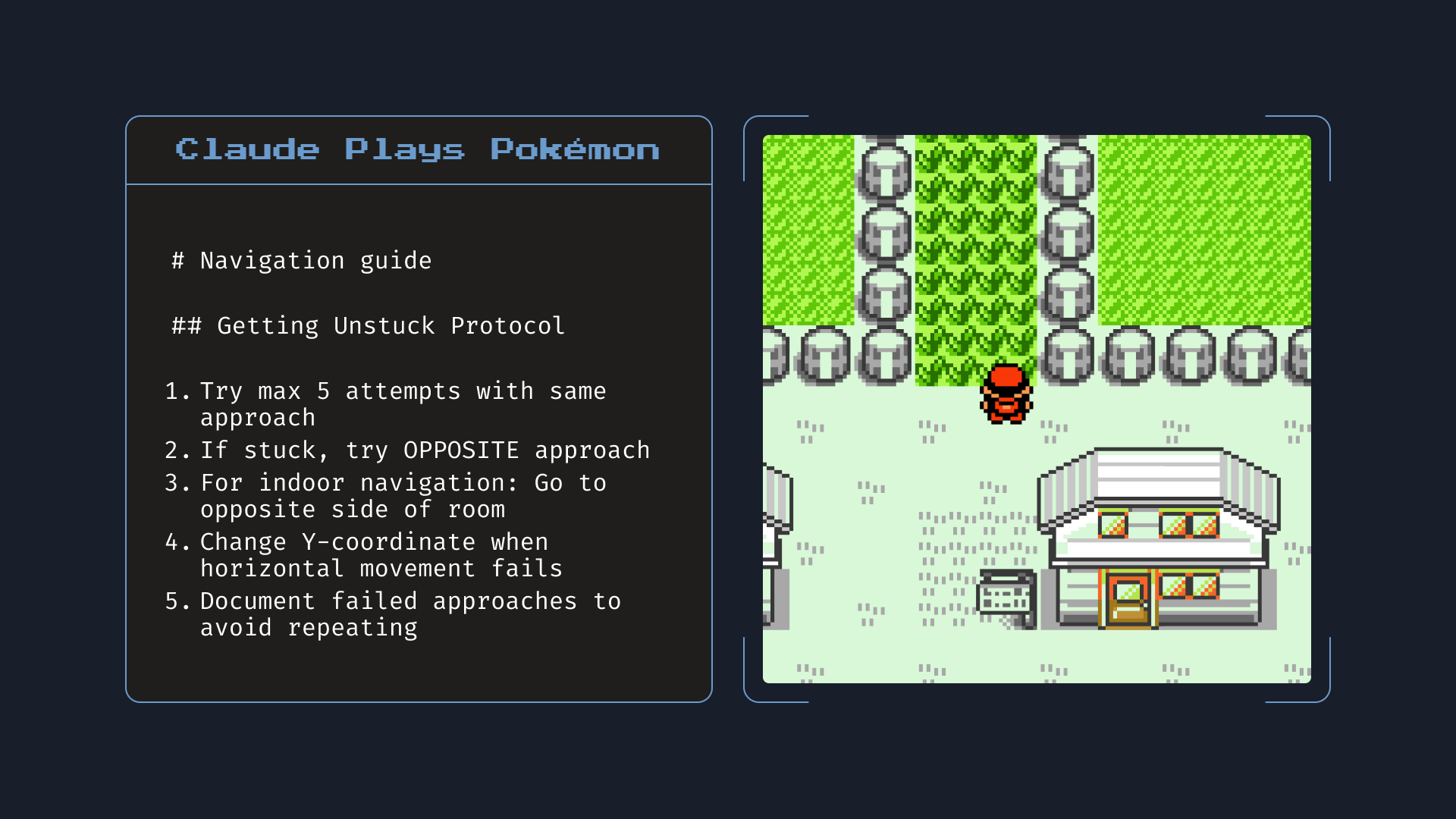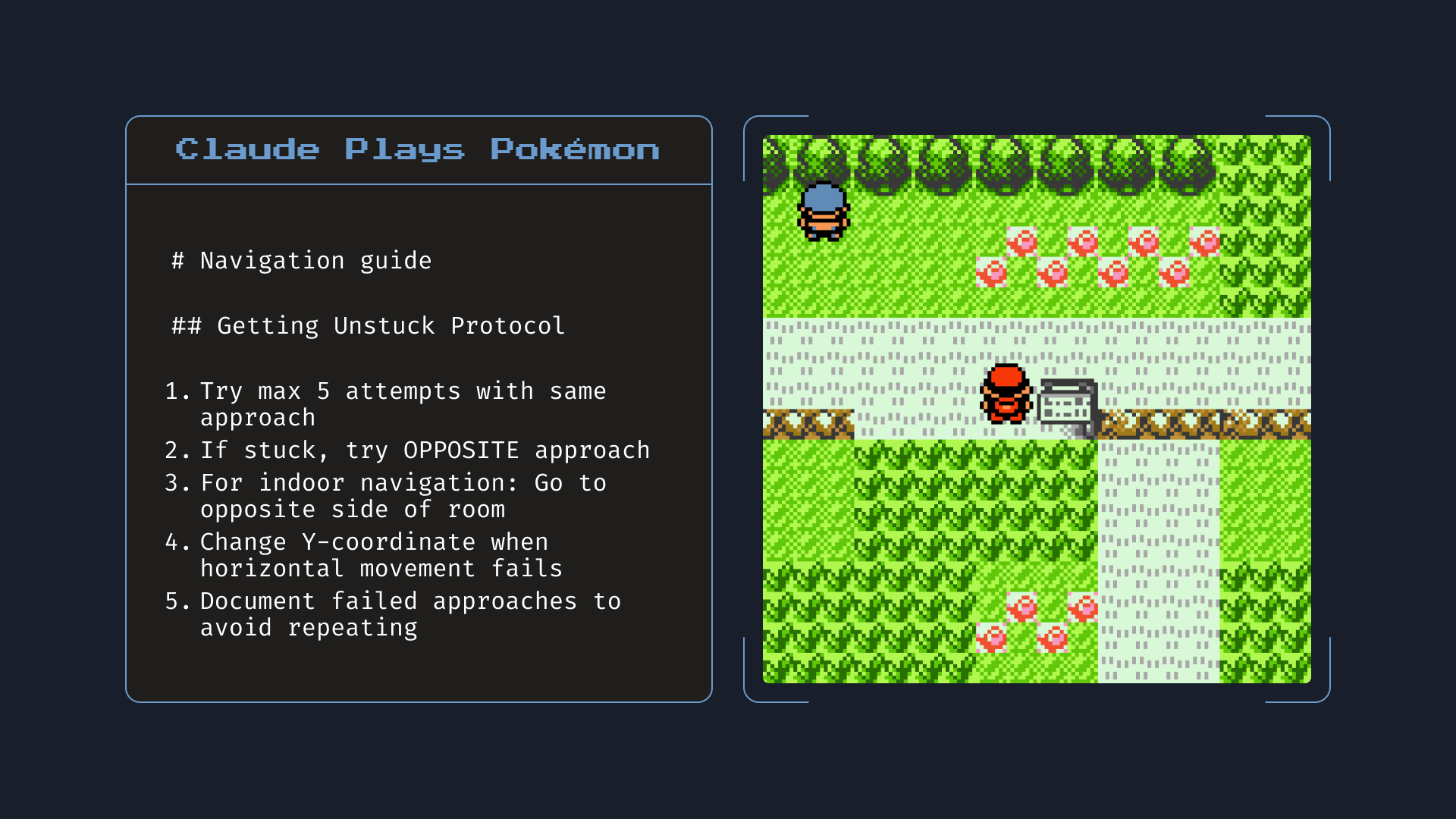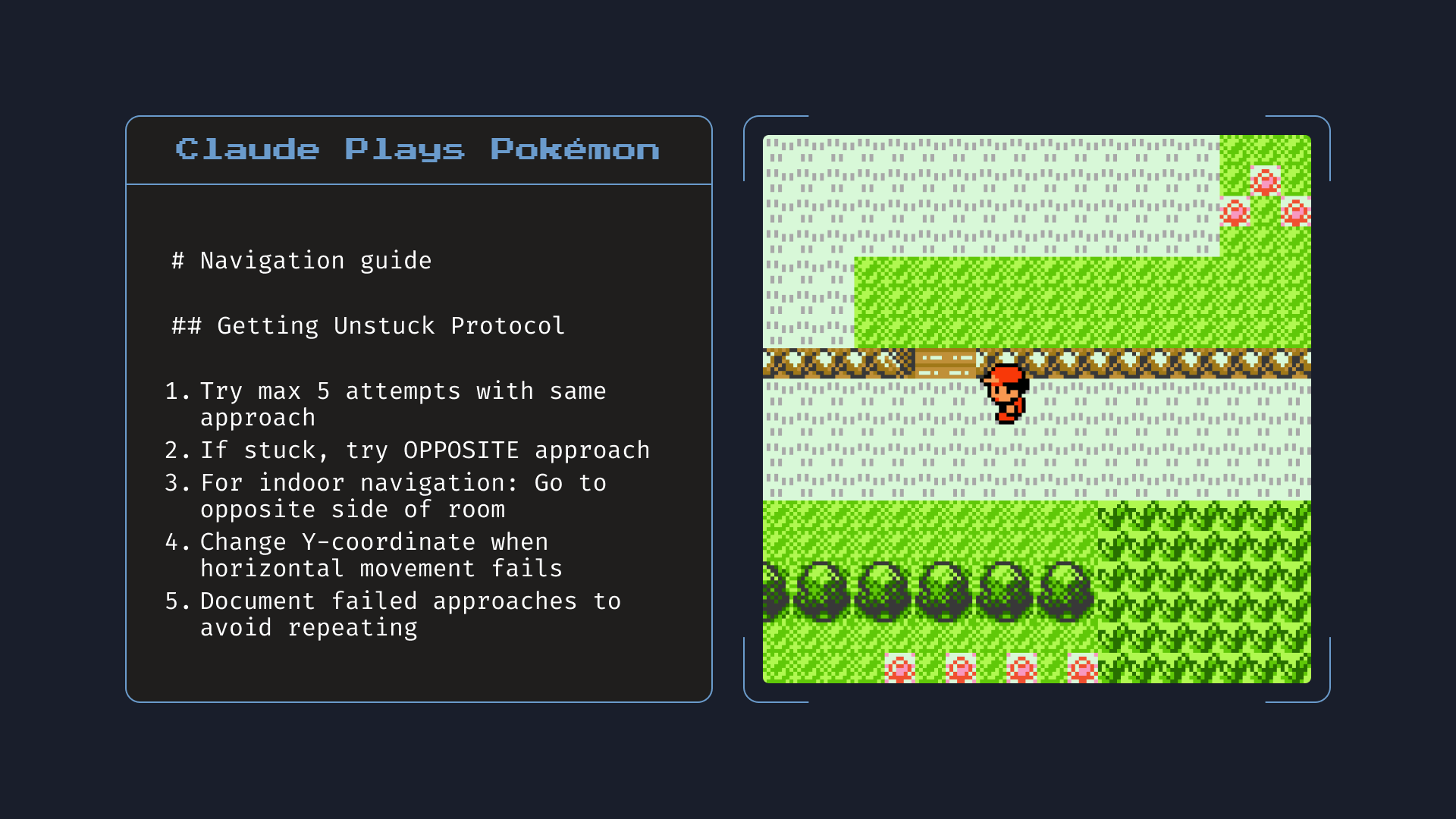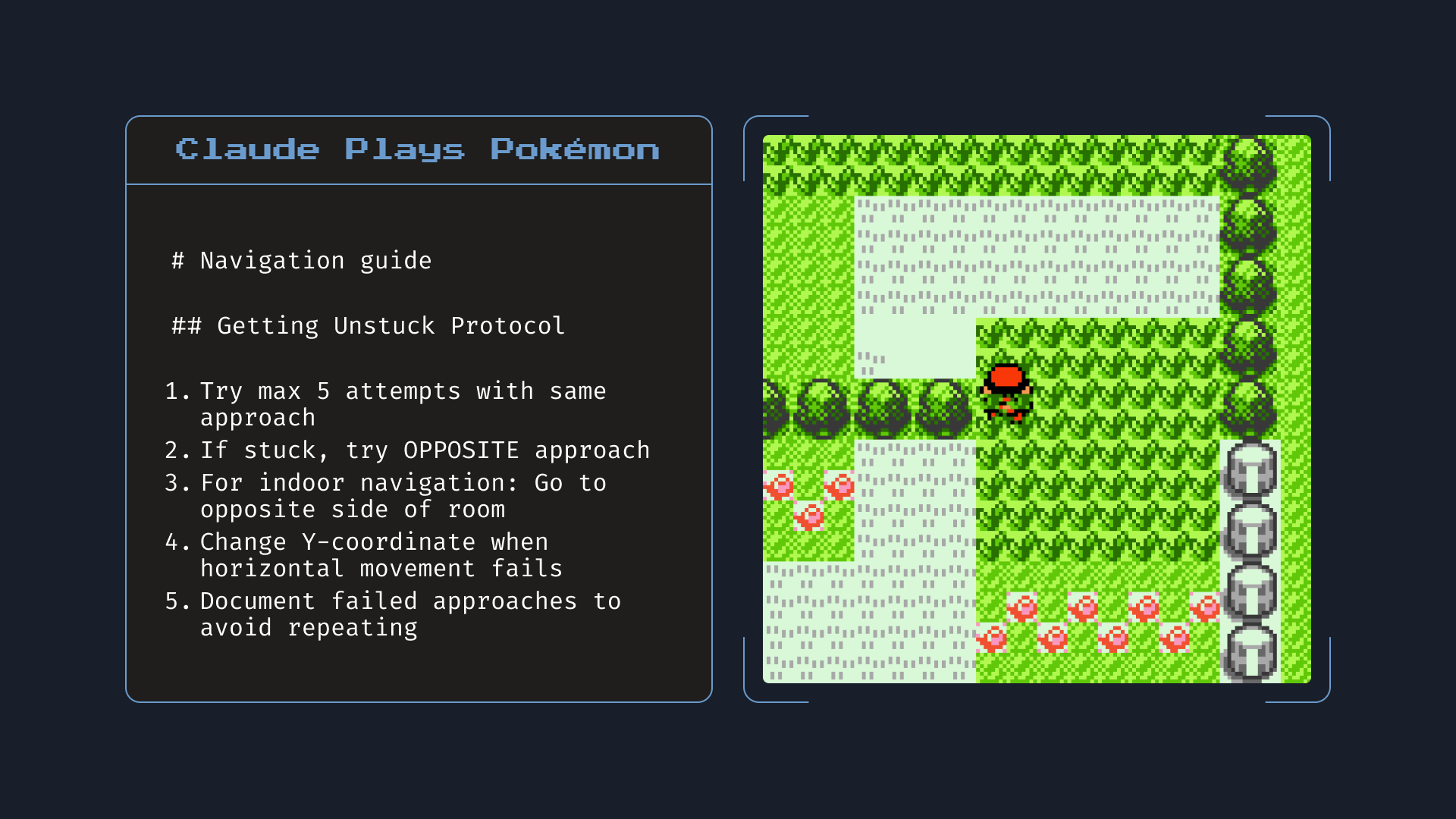
官方演示:给本地文件访问权限后,Opus 4 在玩《宝可梦红》时自己写了一份「导航指南」记下关键信息,帮助后续游戏。图为 Opus 4 真实记下的笔记。来源:Anthropic
Opus 4 与 Sonnet 4 怎么选
Opus 4
最强编程,长任务连续数小时
- SWE-bench Verified
- 72.5%
- Terminal-bench
- 43.2%
- 价格 / 百万 token
- 输入 $15 / 输出 $75
- 免费用户
- 否,限 Pro / Max / Team / Enterprise
Sonnet 4
高性价比日常,Sonnet 3.7 升级
- SWE-bench Verified
- 72.7%
- Terminal-bench
- ,
- 价格 / 百万 token
- 输入 $3 / 输出 $15
- 免费用户
- 是,免费可用
关键数据
72.5%
Opus 4 在 SWE-bench Verified 的得分
72.7%
Sonnet 4 在 SWE-bench Verified 的得分
43.2%
Opus 4 在 Terminal-bench 的得分
$15 / $75
Opus 4 每百万 token 输入/输出价格
$3 / $15
Sonnet 4 每百万 token 输入/输出价格
低 65%
官方称两款在易投机 Agent 任务上走捷径的概率,比 Sonnet 3.7 更低
约 5%
思考过程长到需用小模型做摘要的占比,其余直接全文展示
SWE-bench Verified 得分
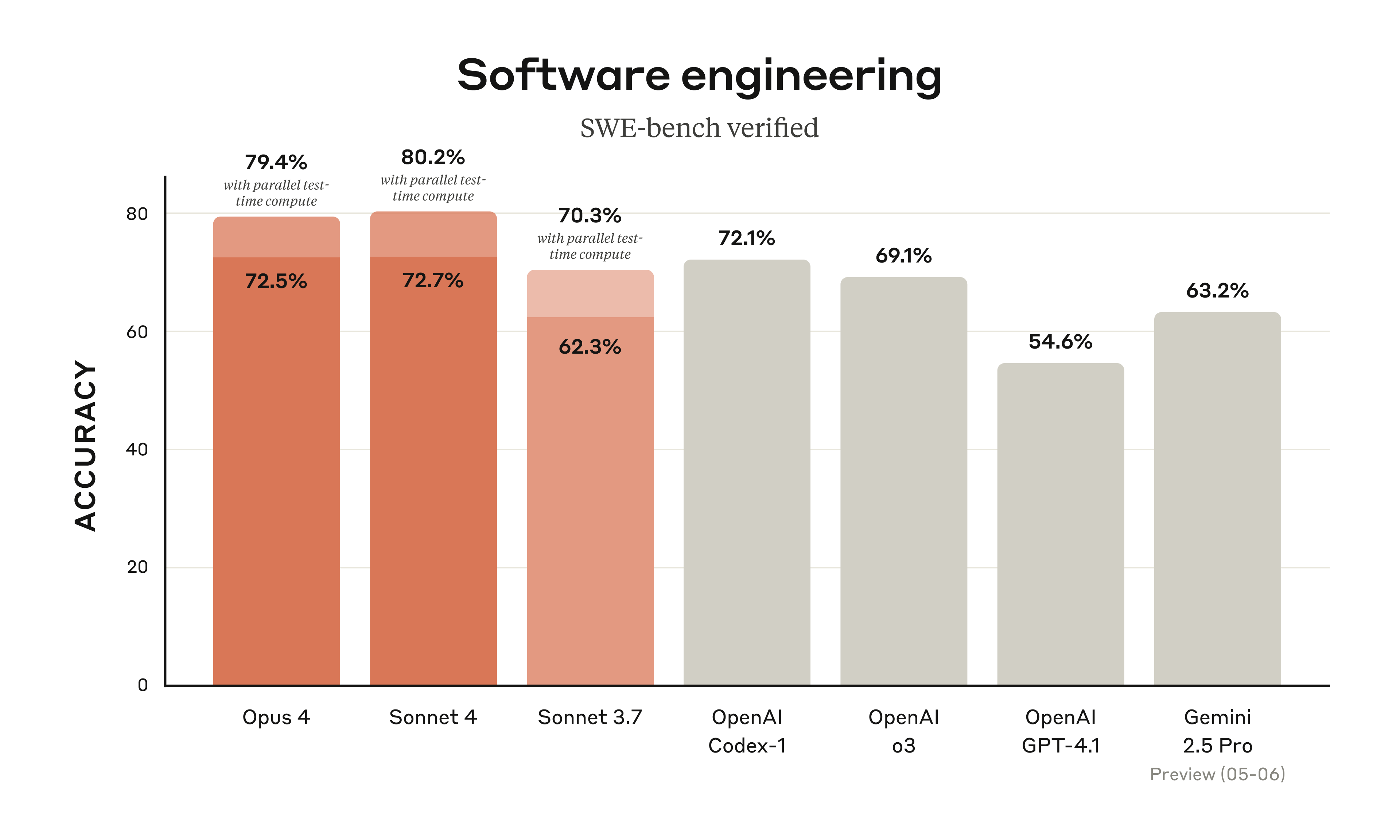
官方给出的 SWE-bench Verified 跑分柱状图,Claude 4 两款与 OpenAI、Gemini 等模型对比。所有数据为 Anthropic 官方自测口径,竞品分取自各家公开材料。来源:Anthropic
官方确认 vs 外界推测
✓ 官方确认
- 定价:Opus 4 $15/$75、Sonnet 4 $3/$15,与上代 Opus、Sonnet 持平。
- 上线渠道:Claude 各付费套餐 + API + Amazon Bedrock + Google Vertex AI;Sonnet 4 对免费用户开放。
- Claude Code 转为正式版(GA),含 VS Code/JetBrains 插件、GitHub 集成和可扩展 SDK。
- 新增 4 项 API 能力:代码执行工具、MCP 连接器、Files API、最长 1 小时的提示缓存。
- 两款均为混合模型,提供即时回答与扩展思考两种模式。
≈ 外界推测 / 厂商措辞
- 「全球最强编程模型」是 Anthropic 自己的措辞,所列 benchmark 也均为官方自测。
- benchmark 取「用或不用扩展思考的最高分」;TAU-bench 还加了提示词补丁,并把最大步数从 30 提到 100,测试条件偏有利。
- Cursor、Replit、Rakuten「连续运行 7 小时」、iGent「导航错误从 20% 降到接近零」等均为合作方单方说法或单一案例。
- 「能连续工作数小时」「迈向虚拟协作者」属趋势性表述,不是可复现的硬指标。
Claude Opus 4 是我们迄今最强的模型,也是全球最好的编程模型,在 SWE-bench(72.5%)和 Terminal-bench(43.2%)上领先。 Anthropic,《Introducing Claude 4》, 2025-05-22
来源:Anthropic 官方发布《Introducing Claude 4》(2025-05-22,anthropic.com/news/claude-4)。文中所有 benchmark 数据均为 Anthropic 官方自测口径,竞品分数取自各厂商公开材料;Cursor、Replit、Block、Rakuten、Cognition、GitHub、Manus、iGent、Sourcegraph、Augment Code 等表述为对应公司的单方说法。本页可视化由小互解读站绘制。